Built-In Evaluation Metrics for Image and Video Models
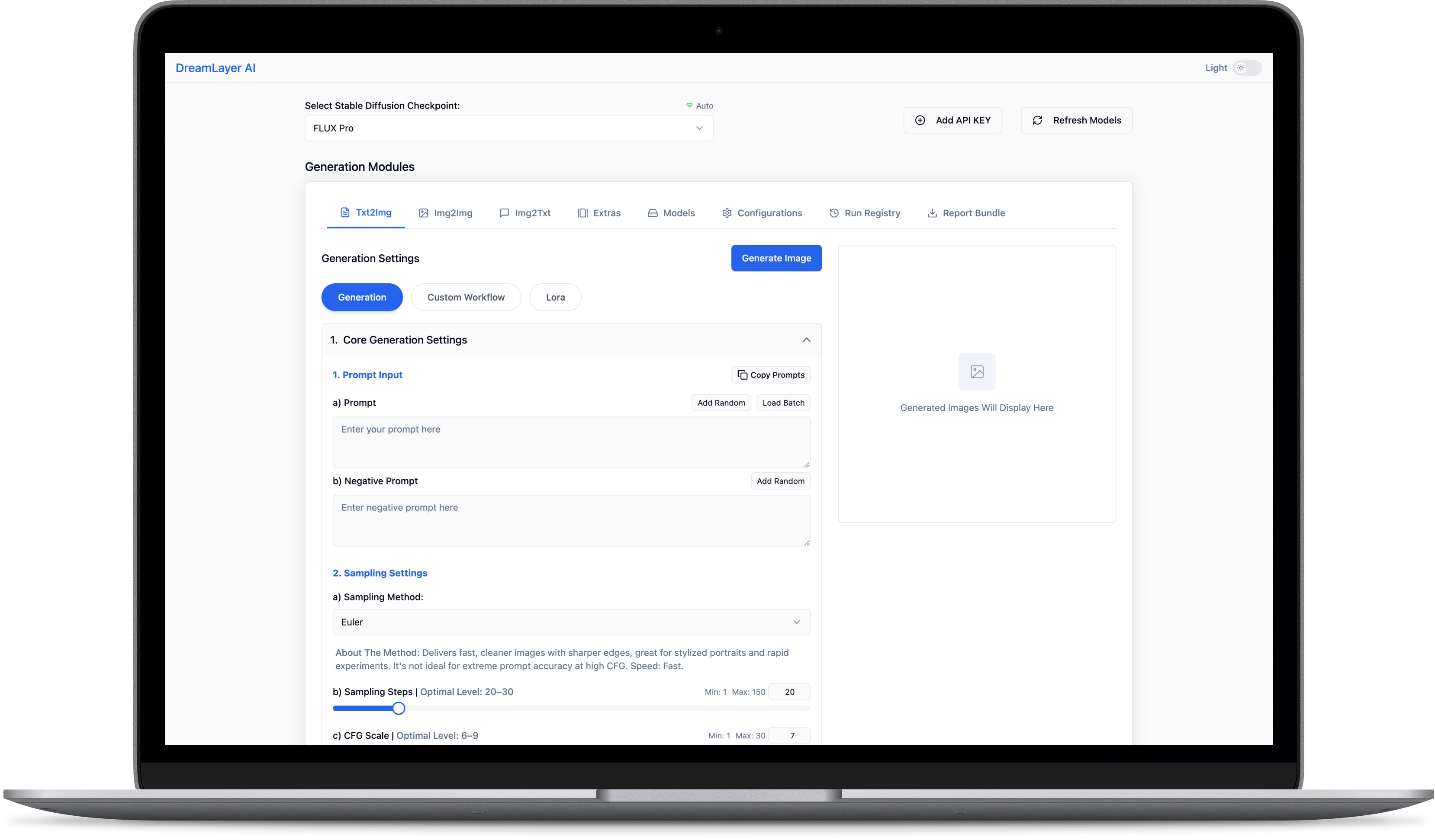
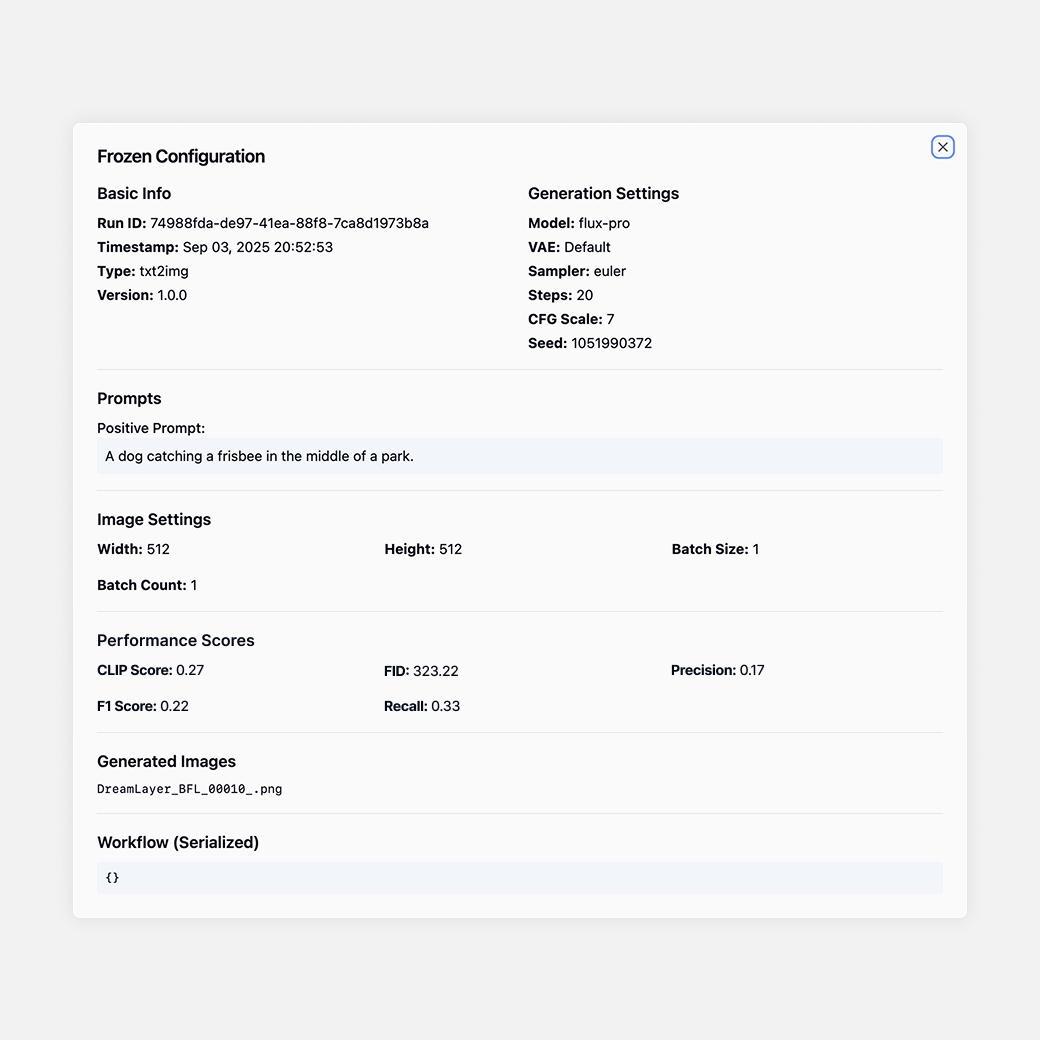
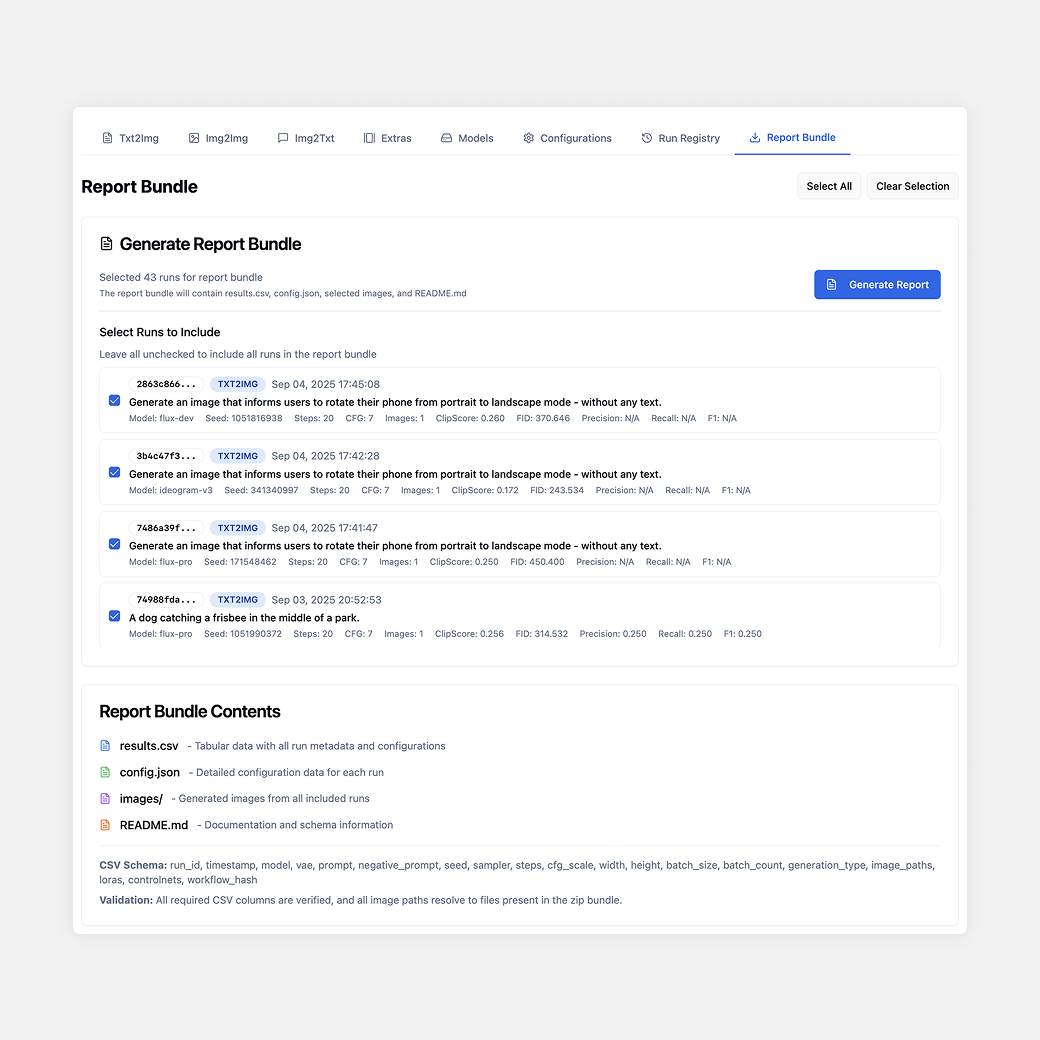
DreamLayer supports common image and video evaluation metrics for benchmarking model outputs, including CLIP Score, FID, precision, recall, F1, LPIPS, SSIM, PSNR, and temporal consistency metrics.
CLIP Score, FID, precision, recall, and F1 logged automatically
Metrics tied to prompts, seeds, outputs, and configs for full traceability
Export-ready evaluation results for papers, reports, and leaderboards